 Miniyacc
Miniyacc
A Lightweight Yacc for C
This single-file program implements a useful subset of POSIX yacc. It lets you describe a language with an unambiguous LALR(1) grammar and compiles it into a fast C parser for that language. Because it is so simple, you can use it to learn about parser generation. You can also use it to quickly bootstrap a yacc for another language. Finally, because it is standalone and under MIT/X license, you can integrate it very easily in your programs.
- Get a working version of yacc.c.
Compilation is as simple ascc yacc.c -o yacc. - Read the MIT/X license.
- You can browse the source.
Or check it out atgit://c9x.me/miniyacc.git.
Example
Here is a complete minimal example to get started. You can
compile it using yacc xmpl.y && cc y.tab.c.
Then use the input "2*(3+4*3+1)" to test it, for example.
%{
#include <stdio.h>
int yylex(void);
%}
%token INT
%left '+'
%left '*'
%%
prog: expr { printf("-> %d\n", $1); } ;
expr: INT
| '(' expr ')' { $$ = $2; }
| expr '+' expr { $$ = $1 + $3; }
| expr '*' expr { $$ = $1 * $3; } ;
%%
int yylex() { /* crude lexer */
int c = getchar();
if (c >= '0' && c <= '9') {
yylval = c-'0';
return INT;
}
return c == EOF ? 0 : c;
}
int main() { return yyparse(); }
Features
- Short and hacker-friendly C89 implementation.
- Mostly POSIX (-b, -d, and -v are supported).
- Standalone (the skeleton code is in the source).
- Generated tables are as efficient as GNU bison's.
- Reasonably fast implementation (<1s for 500+ grammar rules).
- Supports
#linedirectives.
The two main features lacking to make it fully POSIX compliant are error recovery and mid-action rules (although these can be emulated by adding a few extra non-terminals with an empty production). Negative references into the parsing stack are also unsupported.
Hacker's Guide
Yacc is a complex program, to understand it one must first understand the basics of shift-reduce parsers and get a high level idea of how LR state generation goes. I cannot cover these topics here because I know I will make a poor job at it. The Dragon Book has excellent coverage for them and the first edition (which is more than enough) can be found for a couple of dollars on Amazon (I bought one there and I'm extremely happy with it). If you contact me in person, I can provide additional documentation. In the sequel I will assume that you are a bit familiar with the terminology.
My implementation is divided into four parts, the first one deals with straightforward inference of properties on the grammar (is a non-terminal nullable, what is its FIRST set); the second part implements the primitve operations GOTO and CLOSURE on sets of LALR(1) items together with the state generation; the third part figures out the final parsing tables and compresses them; finally the last part and also the simplest deals with all the .y parsing and the .c/.h printing.
With loose discipline, I prefixed most functions of the first three parts
with respectively, g, i and tbl. Also,
the order in which I listed the parts is the order in which you will find
them in the source. This gives you a basic way to navigate the code. What
follows is a high level description of every important function and type.
| Sym | A symbol, if it is smaller than MaxTk it is a token, otherwise it is a non-terminal. No real symbol can be the special symbol S, we use it to mark the end of a string of symbols. |
| Rule | A grammar rule, the lhs field is an array of symbols terminated by the special symbol S. The action field stores the semantic action given in the .y file for this rule. |
| Item | A LALR(1) state, i.e. a set of Term.
The set is stored in an array which is structured as
follows. Elements of the core (which have
their dot not at the very beginning) come first, and
they are sorted according to the icmp order.
Then follows a bunch of items not in the core, they
can be in any order but need to be grouped by lhs.
Here is an example item
E -> E . O E O -> . A A -> . '+' A -> . '-' |
| rfind | Returns a pointer to the first Rule with a given left-hand-side. We use the fact that the rs array is sorted by lhs. |
| first | Computes the set F of initial tokens that can be generated by the given sentence terminated by with element of the last set and union the set passed as first argument with F. |
| ginit | For every non-terminal N, it computes if N is nullable or not and the set FIRST(N) and stores it in the is symbol information array. |
| iclose | Computes the closure of a LALR(1) state. We basically follow the textbook procedure. Note that we make use of the fact that non-core items are grouped by lhs while filling and using the smap array. |
| igoto | Computes the GOTO along a given symbol of a LALR(1) state. |
| icmp | Is non-trivial because it relies on the fact two elements can be compared by only comparing their core. You can see the Dragon Book to understand why (or just think about it). |
| stadd | Is the main workhorse of the state generation routine. It figures out if a state to-be-inserted is already present in the state array (kept sorted using the icmp order) and adds it if not present. An integer is returned to signal if a change occured in the state list or not. |
| stgen | The actual state generation function, here also, we follow the textbook procedure. We use the modified bit returned by stadd to figure out if more work has to be done or not. There is a simple optimization that sticks a dirty bit to every state to know if it is necessary to recompute the GOTOs from this state or not. |
| resolve | Resolves shift/reduce conflicts using precedence and associativity of tokens and rules. The procedure implemented is described in details by POSIX. |
| tblset | Compute the action generated by one Term in a LALR(1) state, it can be a shift or a reduce depending on the position of the dot. This function figures out if the grammar has conflicts or not. |
| setdef | Given a table row, this function figures out the most frequent entry and stores it as default. It is used to get a very sparse table (compact to store). The rows it processes are rows from the action and goto tables. On an action row, it is very often (if not always) that there is only one reduce entry, we use it as default. The goto table, if stored with indexing [state][nonterm] always have entries that are all different (see Dragon Book), to make good use of the default table one must store it with indexing [nonterm][state]. To convince yourself that it is a good idea, your can run yacc.c on a sample grammar with the -v option and check the y.output file. |
| tblgen | Generate the action and goto tables and compute and store their most frequent entry per row. The indexing for the goto table is [nonterm][state], and for the action table it is [state][token]. These different indexing schemes permit to have smaller tables. |
| actgen | The supperficial logic is simple, but as a comment warns, there is a tricky invariant. This invariant has to deal with the way the check table is generated. I will give more details below on how the tables are stored and why we must be careful when generating them. |
| tblout | Dumps the tables using C syntax. |
| nexttk cpycode gettype getdecls getgram | Vogon poetry for parsing. |
| actout | Output the code for one action and substitutes the $$ and friends with regular C code. This is a little complex because we have to do what POSIX calls "type inference", that is, find out what is the union field to use for each of the non-terminals referenced in an action. |
| codeout code0 code1 | Data and simple code to output the final C file. Originally, Yacc was using intermediate files for this generation (POSIX even mentions them). Considering how much memory today's computer have, I did not bother with that and just stored everything in RAM. |
A Yacc program is expected to generate two main tables: the goto table and the action table. In practice, one needs to generate a few more. Here is a description of all the tables generated by the yacc.c program.
yytrnsPOSIX requires that 'c' for every c is a valid token, we use this table to map tokens given by yylex to a smaller range (this makes the tables more compact).yyr1maps a rule number to the arity (number of elements in the rhs) of this rule.yyr2maps a rule number to the lhs symbol of this rule.yyadefmaps a state to the default reduce for this state, or -1 if the state cannot reduce.yygdefmaps a non-terminal to its most frequent GOTO destination. (Remember that the gotos are indexed [nonterm][state].)yyadspmaps states to displacements for actions.yygdspmaps non-terminals to displacements for gotos.yyactcontains actions and gotos, this is the most important table together with the next one.yychkis the checking table foryyact.
The scheme used to store tables in a space-efficient manner uses what we call a row displacement table. The idea is described very well in Robert Tarjan's paper Storing a sparse table, it is also described in section 3.9 of the Dragon Book. I will try to sum it up in a few words. Assume we want to store efficiently a table A with many zeroes inside, we also would like that the access in the compacted table is in constant time. To do this, we linearize the table A into a simple array and overlap the different rows of A to make sure very few zeroes are left. Each original row of A will be assigned a displacement into the linear array. The following figure shows an example of this packing process on a sample table, the r{n} number is the displacement of the original row n. Stars in the A table represent non-zero entries.
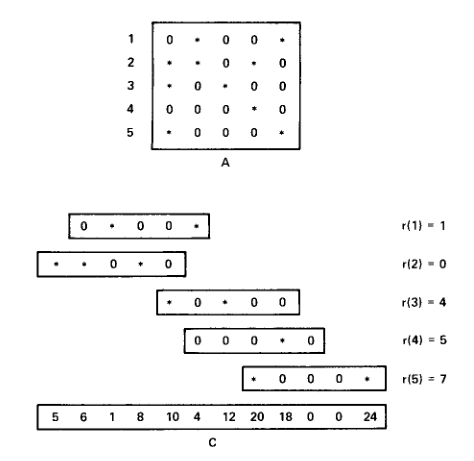
The above figure does not show the table T that stores all the non-zero entries, instead it shows the checking table C. Using the displacements r{n}, it is easy to construct T. The table C is used for retrieval of data: to get the entry A[n][m] (if n and m are 1-indexed) we use the algorithm below.
x := r{n} + m
if (x <= 0) || (x > size of C) || (C[x] != (n-1)*5 + m-1) then
return 0
else
return T[x]
fi
Notice how the C table holds the cell number of the corresponding entry stored
in the A table. It is also sufficient to make C store only the row number
of the entry stored in A, this makes the numbers stored in C smaller and can
help save a few bytes. This is what we do for the goto table: the checking
table yychk stores only non-terminal numbers for validation.
You can see how they are checked in code0, the skeleton code
for C files generation.
The case of the action table is a bit trickier. One
can easily observe that many rows in an action table are often identical,
so we would like to assign these rows the same displacement. This is possible
but what is stored in the checking table needs to be changed. Indeed, the
whole point of the checking table is that no two entries of A can be validated
at the same location in T. One way to make this compression possible is to
store the column number in the checking table instead of the row
number. This way, two same rows can be assigned the same displacement and
will both be correctly validated by the checking table. This explains why
the yychk table checks action entries based on token number
(and not on state number).
We can now discuss the way to find the displacements r{n} used above.
There is a fairly straightforward greedy algorithm that works well for
that (it is explained in Tarjan's paper why). We simply sort the rows
by decreasing number of non-zero entries and greedily assign the first-fit
displacements for all the rows. This explains why there are qsort
calls in the actgen function. You can check that the
displacements for A above were generated with this technique. This is
all nice and simple, but when we play the trick explained in the previous
paragraph we have to be a bit careful. The risk is that a naive implementation
of the algorithm described here could assign the same displacement to
the two following rows.
Colmns 1 2 3 4 5 6 7 8 9
-------+-------------------+
...
Row n | 0 0 3 0 4 0 0 0 6 |
...
Row m | 0 0 3 0 0 0 0 0 6 |
Row m is "included" in row n, a naive implementation could give them
the same displacement, but then, when querying the entry [m][5], one
would get 4 as an answer (becasue the checking table would validate the
column 5 for row n) and not 0! This is a potential source of nasty bugs.
The lesson is that rows must be assigned the same displacement if and only
if they are exactly the same. The loop in actgen makes sure
it is the case by relying on the fact that entries are supplied in
decreasing number of non-zero entries. This is probably the trickiest part
of table generation (and it is also a performance hog), I would be happy
to take your suggestions about that.
I want to conclude these remarks on table generation/compression by saying that if this remains opaque for you, the best we to understand it is to use a very small grammar (infix addition and multiplication for example), run it through yacc.c with the -v option and decypher the code generated using the y.output file, a pen, and some paper. You might even discover a bug that way!